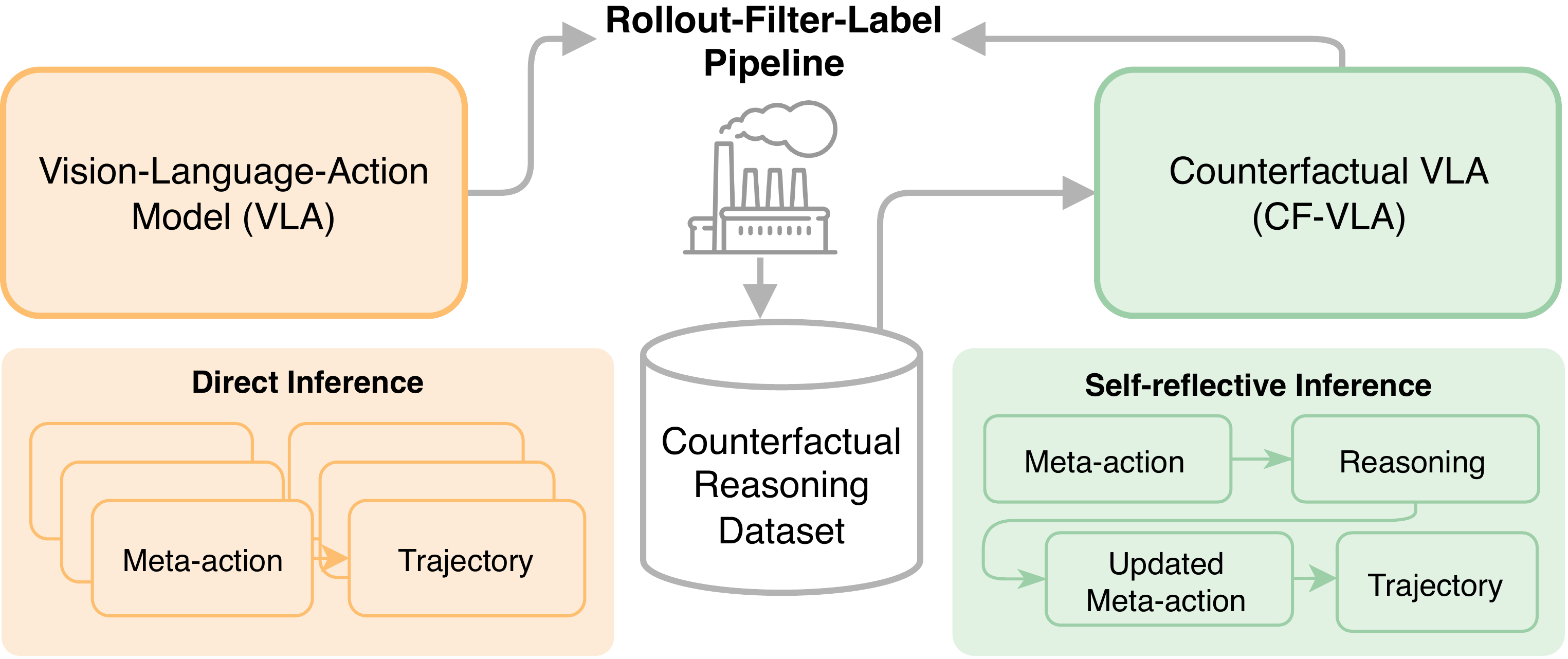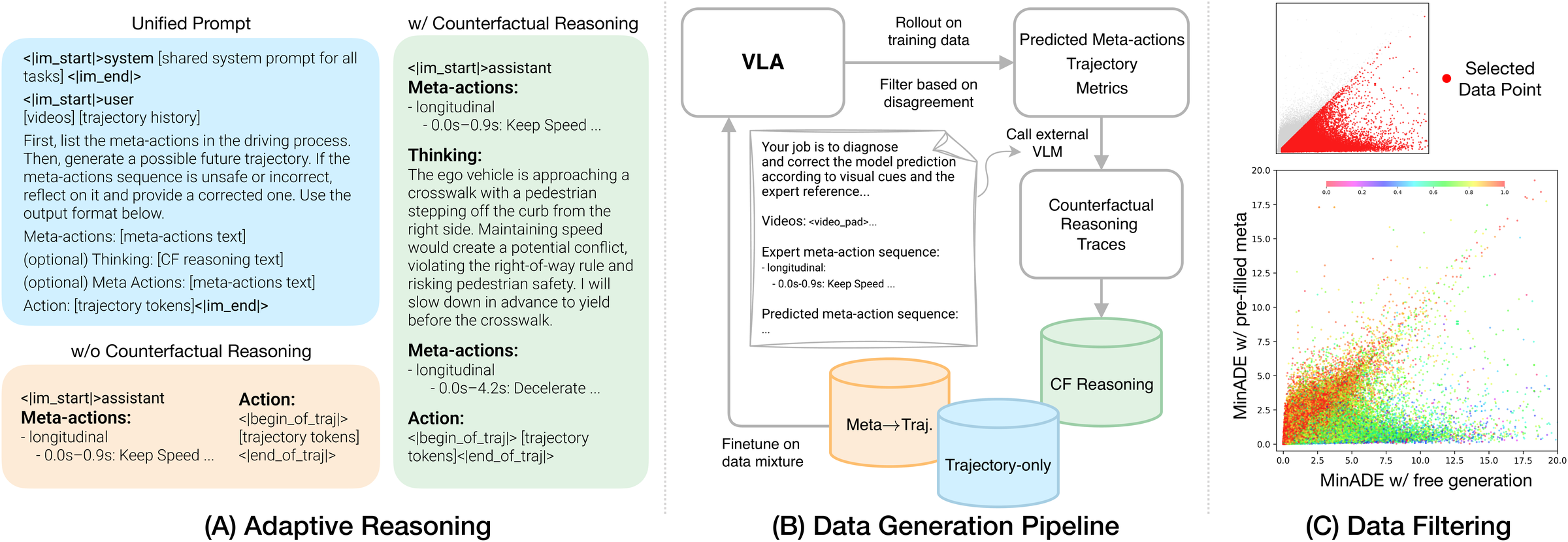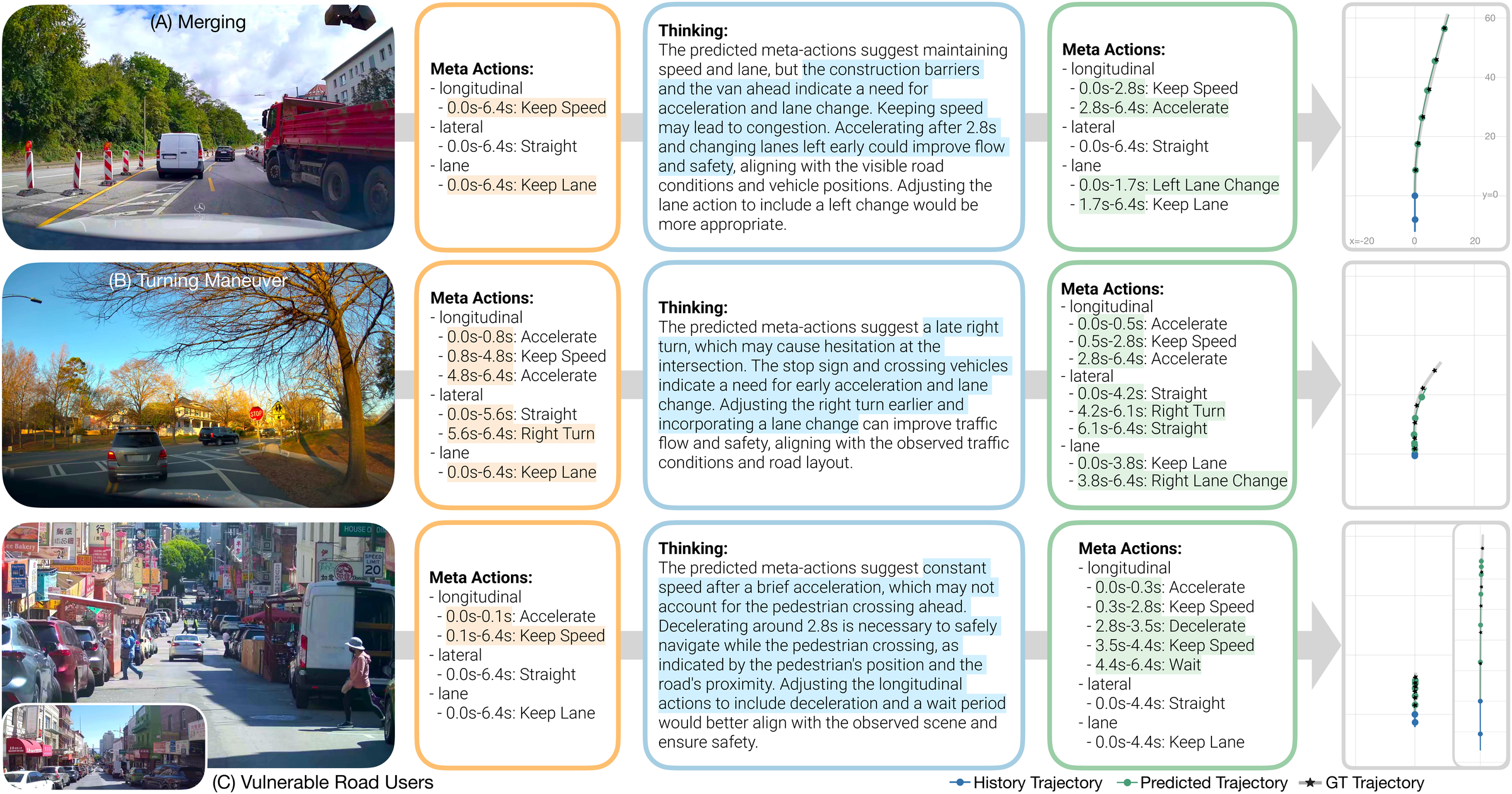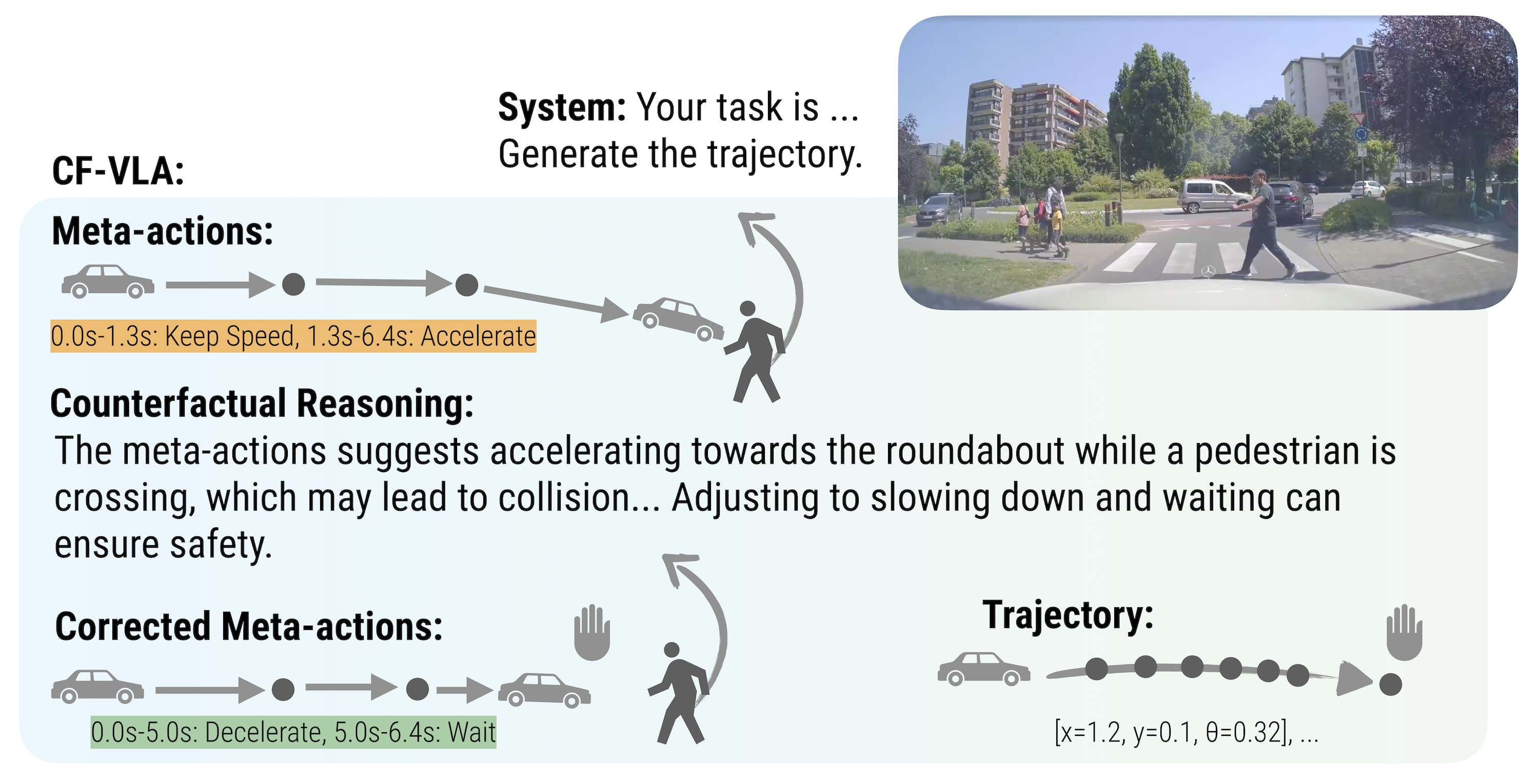
Counterfactual VLA (CF-VLA) reflects on its own action plan and corrects it before generating the final trajectory. In this example, the initial meta-actions suggest accelerating toward a roundabout while a pedestrian is crossing. Through counterfactual reasoning, the model identifies the collision risk and revises the plan to decelerate and wait.