Research Statement
Zhenghao Peng, Aug 18, 2025
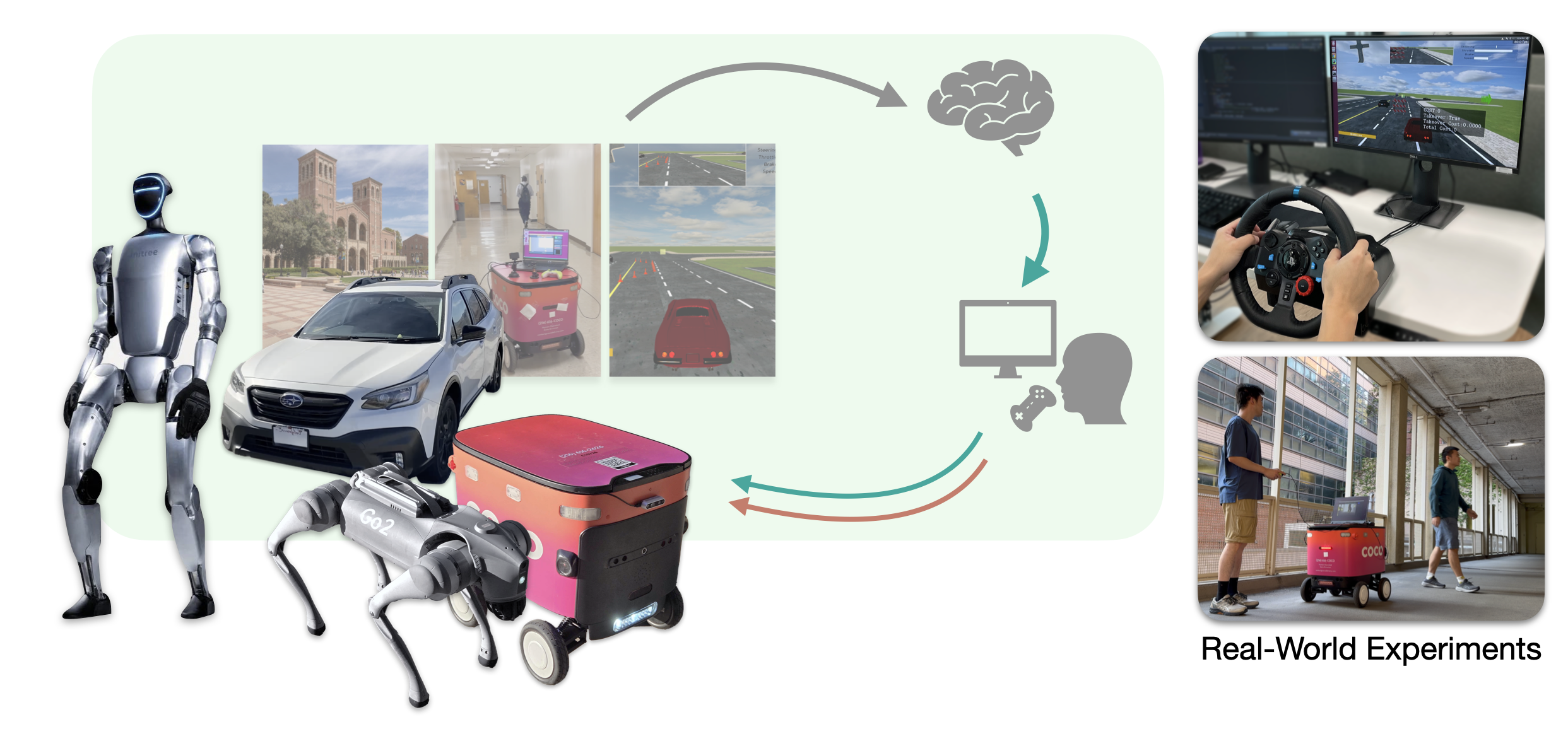
Road to Physical AI
My research aims to build foundation models for robotics that are scalable, aligned, and deployable in the real world.
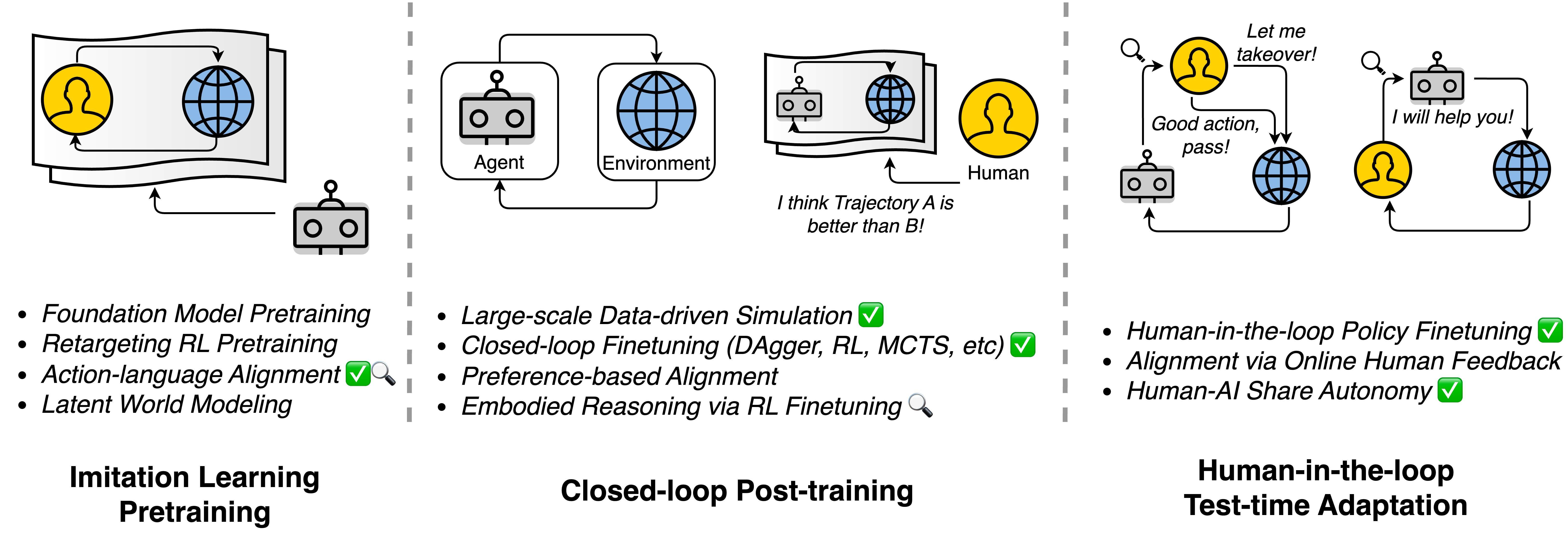
As shown in the figure below, I organize this agenda into three complementary stages:
- Imitation learning pretraining,
- Closed-loop post-training, and
- Human-in-the-loop test-time adaptation.
I started my research in 2018. Since then, I have published 16 papers in top-tier AI and robotics conferences, such as NeurIPS, ICLR, CoRL, ICRA, ICML, ECCV, etc. This research statement provides an overview of my work and future directions in each stage.
Imitation Learning Pretraining
Imitation learning provides the foundation for physical AI. My recent work focuses on Vision-Language-Action (VLA) pretraining to endow models with embodied understanding and action–language alignment.
In MetaVQA, we constructed datasets to provide 3D grounding and physical reasoning to VLAs.
Currently, I am exploring methods to ensure the model understands the actions it produced semantically, enabling reasoning about both execution and consequences.
Closed-loop Post-Training: Simulation and RL

While imitation learning offers strong initialization, open-loop behavior cloning often fails in real deployments. Closed-loop post-training in simulation bridges this gap. I’ve been exploring the methods to improve the fidelity of data-driven simulation.
Simulation Platforms: I built MetaDrive and ScenarioNet, enabling large-scale data-driven simulation. MetaDrive has received 1,000+ GitHub stars and 350+ citations, becoming a widely used benchmark in the community.
Data-driven Environment Generation: InfGen is a multi-agent behavior model that augments dynamic multi-agent traffic situations. CAT and Adv-BMT generate adversarial driving scenarios. We show that training RL agents on the scenarios generated by above models can greatly improve it’s closed-loop performance, showing that improving the dynamic realism of simulation is crucial for closed-loop RL.
Improving Visual Realism: SceneGen (Diffusion models) and Vid2Sim (3D Gaussian Splatting) rerender visual environments from real videos, creating photorealistic RL environments.
Closed-loop finetuning: We can post-train a large transformer model with closed-loop RL finetuning, which greatly improves the multi-agent behaviors.
I am exploring the embodied reasoning as a new way to improve VLA.
Human-in-the-Loop Test-Time Adaptation

Even with large-scale simulation and RL, agents inevitably face a sim-to-real gap when deployed. Closing this gap requires humans in the loop, providing real-time interventions and feedback to align the agent’s behavior with human values.
Over the years, I have pioneered this research direction with 5 papers:
EGPO (CoRL 2021): Our research on human-in-the-loop policy learning began in 2021. The first published work is Expert Guided Policy Optimization (EGPO). In this work, we explored how an RL agent can benefit from the intervention of a PPO expert.
HACO (ICLR 2022): Building upon the methodology of EGPO, and substituting the PPO expert with a real human subject, we proposed Human-AI Copilot Optimization (HACO) and it demonstrated significant improvements in learning efficiency over traditional RL baselines.
TS2C (ICLR 2023): In Teacher-Student Shared Control (TS2C), we examined the impact of using the value function as a criterion for determining when the PPO expert should intervene. The value function-based intervention makes it possible for the student agent to learn from a suboptimal teacher.
Proxy Value Propagation (PVP) (NeurIPS 2023 Spotlight): Considering the reward-free setting, we proposed several improvements to enhance learning from active human involvement. These improvements address issues observed in HACO, including the jittering and oscillation of the learning agent, catastrophic forgetting, and challenges in learning sparse yet crucial behaviors.
PVP4Real (ICRA 2025): Deploying PVP on real robots, we train two mobile robots (Go2 and delivery robot) from scratch, without reward, in real world, in real time. We show that the embodied agents can learn (1) safe navigation and (2) human following tasks within 15 minutes on wall time.
This line of work establishes test-time post-training as the final stage of robotic learning: a continual feedback loop where human guidance ensures safety, adaptability, and alignment.
One interesting direction I’ve explored is assistive AI. Collaborating with Prof. Jonathan Kao, we have built Interventional Diffusion Assistance (IDA), a novel AI framework for dynamically sharing control between human users and AI agents, empowering the human users to achieve better performance in control tasks via the synergy of human and AI assistant. Beyond assistive technology, this direction also holds promise for domains like rehabilitation, prosthetic control, and even high-stakes human–robot collaboration in healthcare or industrial settings.